A Deep Dive into the Search + ReadWeb Design (vs. MCP)
This article shows you how to build agent systems that are cheaper to run and produce better answers. I’ll use a concrete example - the Search assistant in GuideAnts Notebooks - to illustrate the pattern, but the principles apply to any agent system that orchestrates tools.
The core ideas are: abstract complexity behind precise tool definitions (this is where OpenAPI descriptions shine), isolate noisy work in specialized sub-agents, and match model capability to task complexity. I’ll also explain why this approach delivers results that a typical Model Context Protocol (MCP) setup cannot.
The Concrete Flow: Search → crawl → ReadWeb → GetContentFromUrl
The screenshot below illustrates a single user turn where the Search assistant orchestrates multiple tools and subagents.
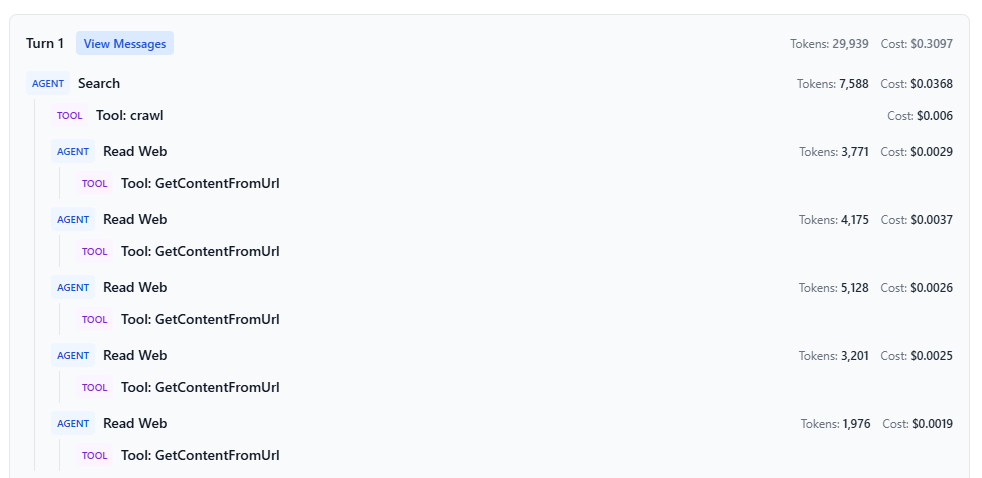
The process begins when the Search assistant receives the user’s query and calls the crawl tool. The crawl tool returns a lightweight set of page titles and URLs relevant to the query - metadata only, with no full page content yet.
For each candidate URL, Search invokes the ReadWeb assistant in an isolated context. ReadWeb uses the GetContentFromUrl tool to fetch and parse the page, then decides whether the page actually contains content matching the user’s query. If no relevant content is found, it simply returns NOT FOUND. However, if it finds relevant material, it extracts and returns only the specific snippets or sections of interest, rather than the entire page.

Finally, the Search assistant aggregates the results. Pages that returned NOT FOUND are effectively discarded, so only the extracted, query-relevant content is brought back into the main context for answer generation. As you can see in the trace (AGENT Search → TOOL: crawl, followed by repeated AGENT Read Web → TOOL: GetContentFromUrl calls), the bulk of tokens are consumed in the main Search turn, while the ReadWeb interactions remain smaller and cheaper.
Why This Design Works: Precise Tools, Isolated Contexts, Early Filtering
Three mechanisms drive the token savings and quality improvements in this pattern.
Precise Tool Definitions. Both crawl and GetContentFromUrl have simple, focused OpenAPI descriptions that hide complexity from the LLM. The LLM never sees how crawling works, how HTML is parsed, or how relevance is scored internally. It only sees a clear contract: “give me URLs for this query” or “extract relevant content from this URL, or say NOT FOUND.” This keeps prompt size small and reduces the chance of incorrect tool usage.
Isolated Contexts. Each page is handled in a separate ReadWeb context. The sub-agent sees only the query and a single URL; it returns either NOT FOUND or a compact snippet. We never load multiple full web pages into the main Search context. This isolation prevents the main agent from being overwhelmed by irrelevant content and keeps each sub-call cheap.
Early Filtering. Because ReadWeb can respond with NOT FOUND, irrelevant pages are discarded before they ever reach the main context. The Search assistant only sees pages that actually contain matching content - and specifically, only the parts that matter. This avoids the common failure mode of stuffing the context with everything a crawler finds and hoping the LLM picks the right pieces.
The result: fewer tokens, less noise, and an LLM that can focus on reasoning and synthesis rather than sifting through garbage.
Model Specialization: The Cost Multiplier
Beyond token savings, this design enables a powerful cost optimization: running different models for different roles.
The Search assistant handles the complex work - reasoning about the user’s intent, synthesizing information from multiple sources, and writing a coherent answer. This requires a capable (and expensive) model.
The ReadWeb assistant has a much simpler job: fetch a page, decide if it’s relevant, extract the good parts. This is mostly pattern matching and extraction, not deep reasoning. It can run on a mini model that costs approximately 10x less per token.
Because the architecture isolates these roles, you can make this tradeoff cleanly. Most of the “web reading” cost is paid at mini-model rates. The expensive model is reserved for the synthesis work that actually requires it. In a typical search query that touches 5-10 pages, this can reduce total cost by 50% or more compared to running everything on a single large model.
How This Differs from MCP
The Model Context Protocol (MCP) standardizes access - it gives you a consistent way for agents to discover and call tools across different servers. This design optimizes interfaces and execution.
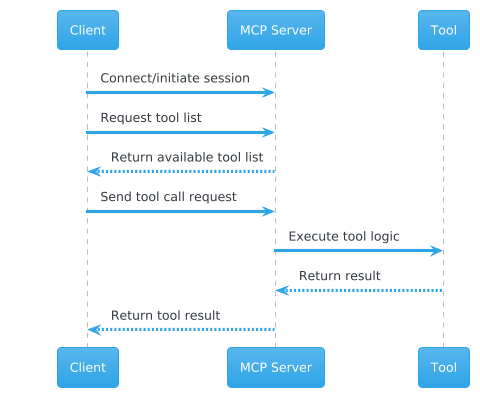
MCP typically exposes tools at the server level and returns raw tool responses directly to the LLM. The client or LLM is responsible for filtering and interpreting the data. This is fine for simple tools, but for complex operations like web search, it means the LLM sees everything the tool returns - relevant or not.
In contrast, this Search design uses assistant-specific tool abstraction. Search sees a high-level crawl tool and a ReadWeb assistant (not a raw HTTP client). ReadWeb sees a specialized GetContentFromUrl tool (not a generic web fetcher). Response filtering and compression happen at the tool or assistant level - NOT FOUND vs. “here is the exact snippet” - before anything reaches the main context.
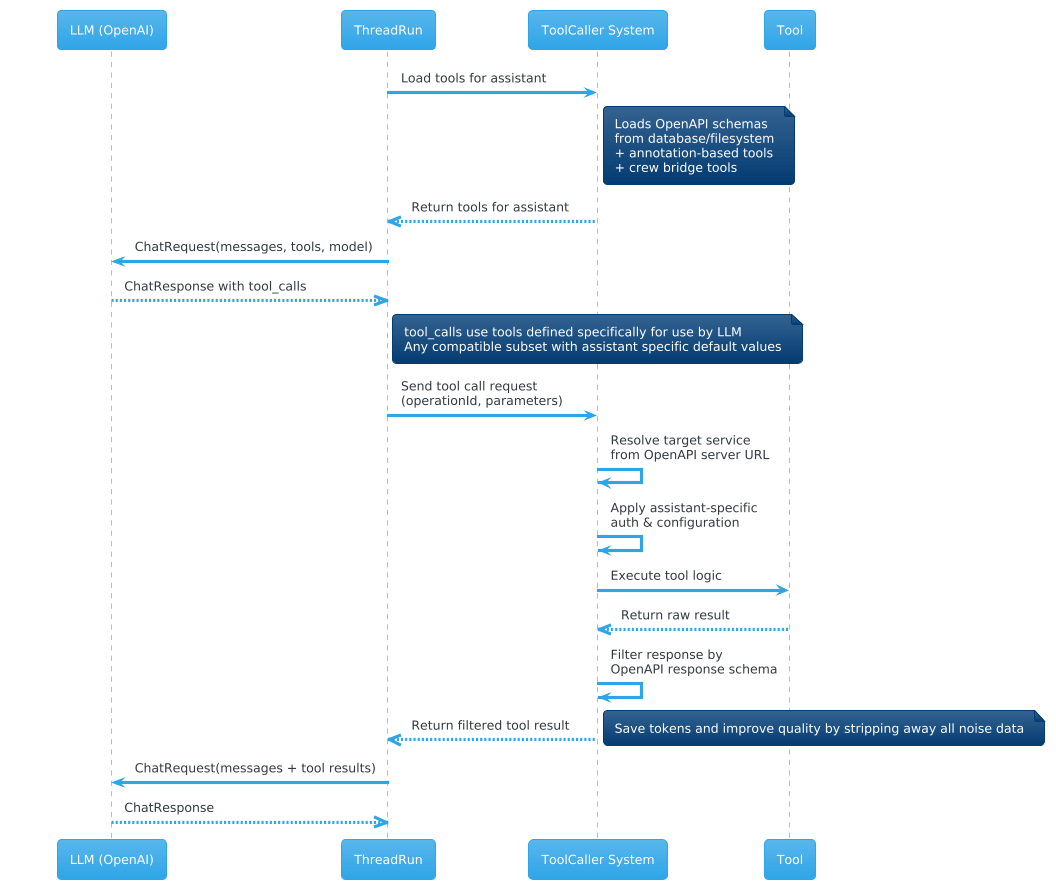
You can think of it this way: MCP standardizes how agents talk to services. This pattern optimizes what agents see and how much they pay to see it.
The two approaches aren’t mutually exclusive. You can use MCP for tool discovery and transport while still applying these abstraction and specialization patterns within your agent architecture.
Takeaways for Any Agent System
These patterns apply far beyond search. Any time you’re building an agent that orchestrates tools, consider:
Specialized Roles. Split complex workflows into an Orchestrator that manages high-level reasoning and Specialized Workers that handle noisy or expensive sub-tasks. The Orchestrator should never see raw, unfiltered data from the outside world.
Precise Tool Definitions. Don’t expose raw APIs to your agents. Create task-specific abstractions with clear contracts. OpenAPI descriptions are ideal for this - they let you define exactly what parameters the LLM can use and what shape of response it will receive, hiding everything else.
Model Specialization. Match model capability to task complexity. Use mini models for extraction, filtering, and formatting. Reserve your strongest models for synthesis and reasoning.
Filter at the Source. Don’t dump raw tool output into your main context and hope the LLM figures it out. Filter early, compress aggressively, and let irrelevant results die in the sub-agent that found them.
The goal is simple: give your main agent only the signals that matter, at the lowest possible cost.